




Article is about web scraping from single HTML document using beautiful soup python module. Step-by-step guide to do web scraping with beautiful soup. You should have basic knowledge about html tags and python programming language.
There are three main python modules that are used for web scraping:
Beautiful Soup -
This articleBeautiful Soup parses a
single HTML documentso you can get data out of it in a structured way.Scrapy
Scrapy is a
comprehensive scraping frameworkthat recursively follows links based on rules you can set and automates a lot of the most onerous minutiae of scraping large amounts of data.Selenium
Selenium is an entirely different tool, a
browser Automatorthat has many purposes besides scraping, but can be used to make scraping more efficient, mostly by rendering JavaScript and other dynamically populated data into HTML that is then readable by Scrapy or BeautifulSoup without having to perform direct HTTP requests or use something like Splash to render the JavaScript.
Here is step-by-step process to do web scraping. You would have to change the code to get the desired html tags, and target them to get the desired data from the website. The process will remain the same, mostly.
Before getting Started install bs4 :
In terminal using pip
pip install beautifulsoup4
conda
conda install -c beautifulsoup4
Step 1: Getting the Source/Data
This is the website that you want to scrape data from. For this tutorial I will be scrapping positive affirmations from a url.
Url: - loudlife35.com/2019/06/500-positive-affirma..
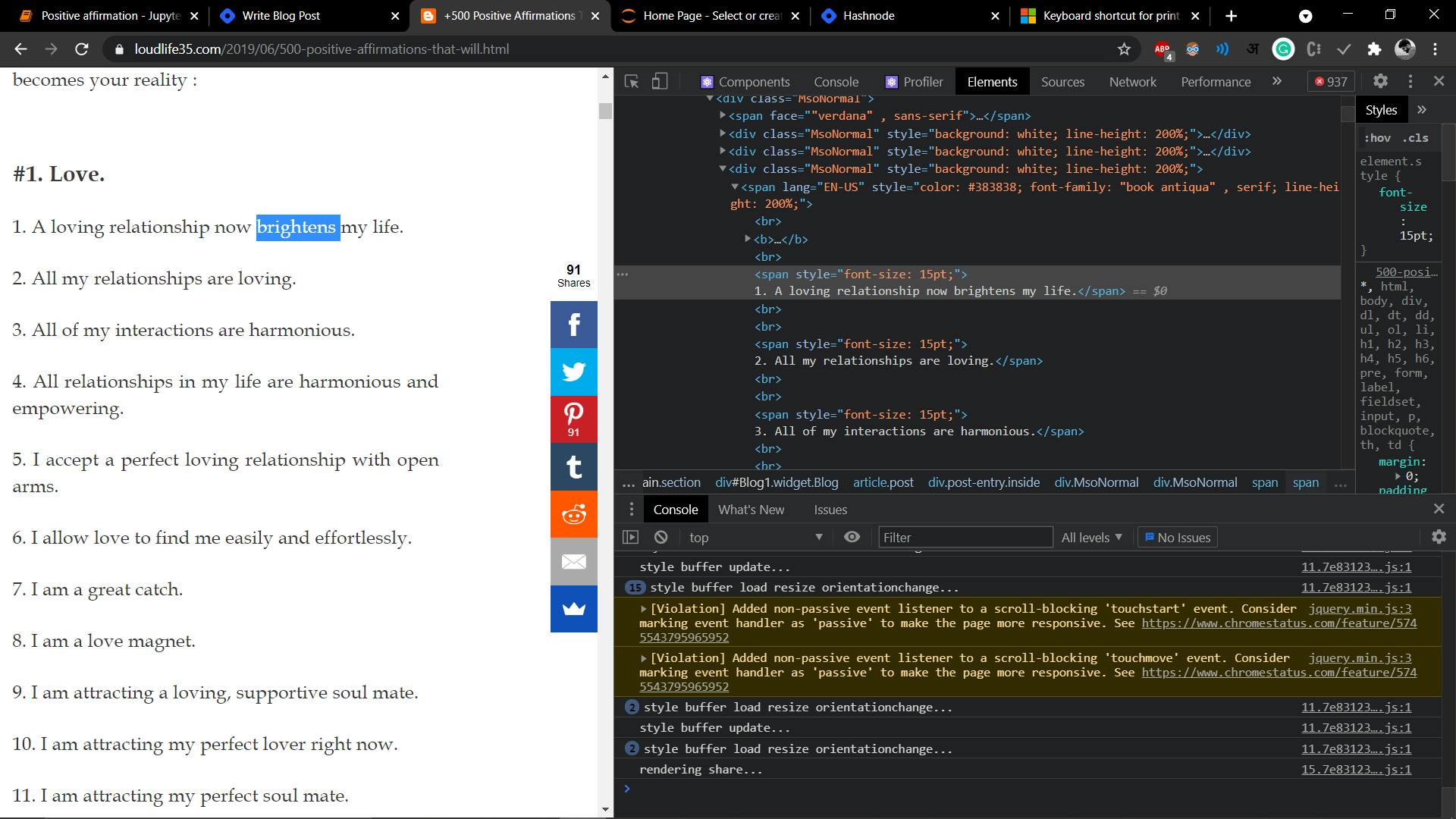
Here, you can see my target html tag is a <span> with the style attributes of font-size (15pt).
Before you start scraping a web page, open up chrome dev tools with ctrl+I. See the html document structure. Html is made of nested tags, so the target tag of you will be nested deep within the document. Also, you might want to get multiple tags from a website.
Step 2: Read the web page with python
The requests module allows you to send HTTP requests using Python.
The HTTP request returns a Response Object with all the response data (content, encoding, status, etc).
Make a request to a web page, and print the response text.
import requests
r = requests.get('https://www.loudlife35.com/2019/06/500-positive-affirmations-that-will.html')
print(r.text[:500])
There is not further use of request module if you want to learn more about the request module and sending other types of http requests such as DELETE, PUT, POST
read here: - w3schools.com/python/module_requests.asp
Step 3: Parsing the HTML using Beautiful Soup
beautifulSoup provides us which methods such as find and find_all to search for specific tags that we want to find. The data you want from a website will be inclosed by some html tags that's what we need to find on a webpage.
importing BeautifulSoup from bs4
from bs4 import BeautifulSoup
Parsing the html using beautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
Step 4: Collecting all of the records
There are two method that are provided in the beautiful Soup module to find specific tags.
find_allfind_all method is used to find all the similar tags that we are searching for by providing the name of the tag as argument to the method. find_all method returns a list containing all the HTML elements that are found. Following is the syntax:
find_all(name, attrs, recursive, limit, **kwargs)example: To find all the p tags do this:## finding all p tags p_tags = soup.find_all("p") print(p_tags)findfind method is used to find the first matching tag.
p_tag = soup.find("p") print(p_tag) print("----------") print(p_tag.text)
As, i have mentioned above html tags that we want are the tag with style attribute of font-size. We can find all of the records with the find_all method in beautiful soup. The method takes first parameter - tag and the second - attributes.
results = soup.find_all('span', attrs={'style':'font-size: 15pt;'})
Now what we get is a list of all the span tags.
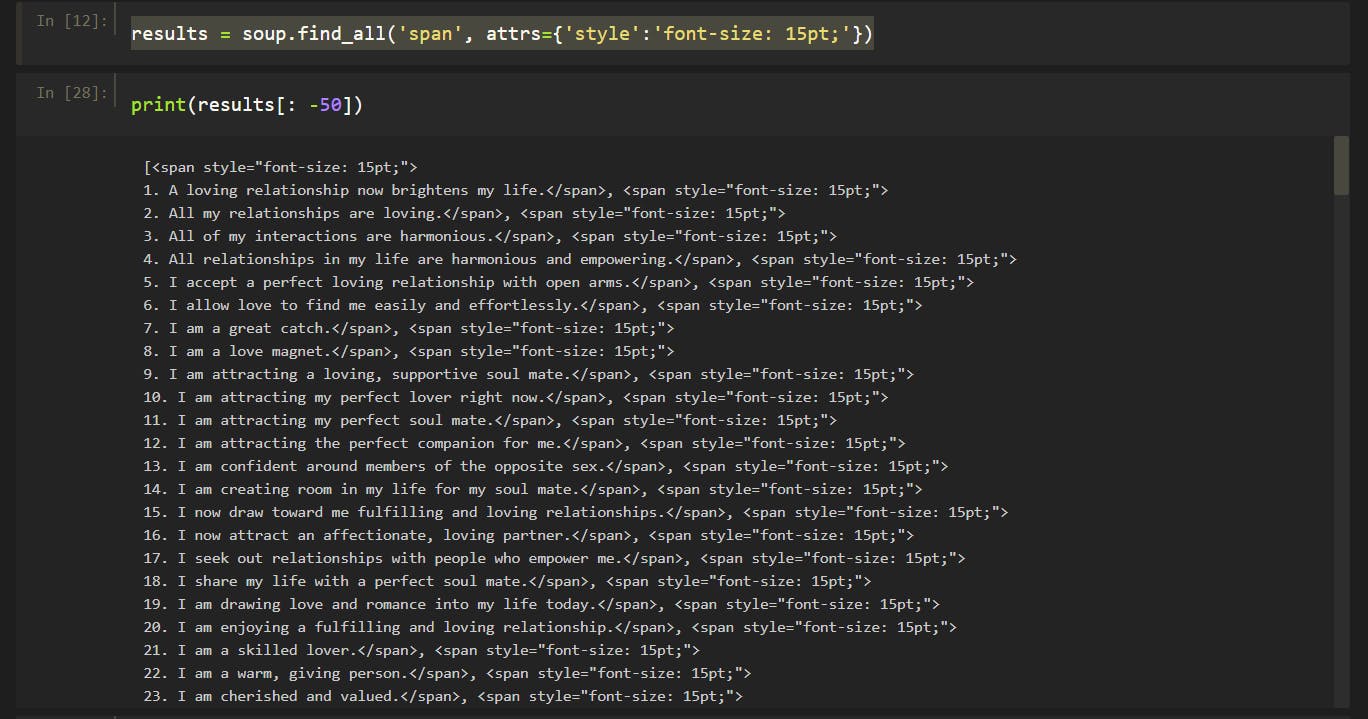
Data cleaning
Our data contains - html tags, numbers.
records[0], look like this.
<span style="font-size: 15pt;">
1. A loving relationship now brightens my life.</span>
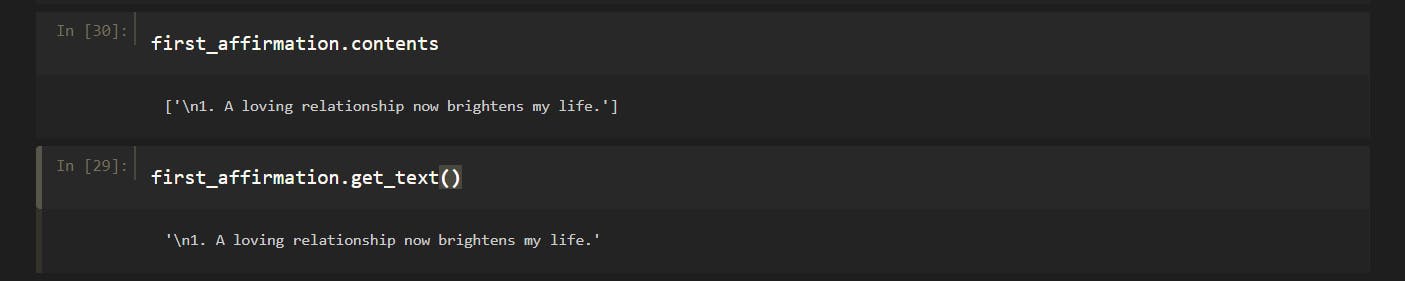
To get the content with in the html tags, beautiful soup have two methods.
.get_text() --> The get_text() method returns the text inside the Beautiful Soup or Tag object as a single Unicode string.
.contents --> A tag’s children are available in a list called .contents.
We can remove the numbers by regular expression. But i don't know that so i just used a python way of doing that.
Nah, But seriously regular expression are great when you are scraping the web.
first_affirmation.contents[0][4: -1]
'A loving relationship now brightens my life'
Step 5: Extracting the data
Create a list.
Loop through all the target htmls tags. A bit of removing the unwanted characters.
And append it to the list.
aff = []
for result in results:
affirmation = result.contents[0][4: -1]
aff.append(affirmation)
Step 6: Building the dataset
Using pandas library we can create a dataset and export the data frame as .csv file.
import pandas as pd
df = pd.DataFrame(aff,columns=['Affirmation'])
Step 7: Creating a CSV file with pandas
df.to_csv('cleaned_positive_affirmations', index=False, encoding="utf-8")
Summary of the beautiful Soup methods and attributes
You can apply these two methods to either the initial soup object or a tag object.
- find(): searches for the first matching tag, and returns a Tag object
- find_all(): searches for all matching tags, and returns a ResultSet object
You can extract information from a tag object using these two attributes:
- text: extracts the text of a Tag, and returns a string
- contents: extracts the children of a Tag, and returns a list of Tags and strings
A simple Exercise:-
If you have followed it now, i want you guys to add a tag column in our dataset.
here is the dataset if you want to see.
kaggle.com/pratiksharm/positive-affirmation..
Word cloud I created from that.

Some Tips
Create a different conda environment for web scraping.
Use chrome dev tools to get the html tag
Use Jupyter notebook instead of a IDE
Any feedback? Hope you liked the article :)